
티스토리 뷰
- 이 글은 글 하단의 Reference에 있는 강의, 교재를 보고 정리한 것입니다.
4.0 Intro
앞서 학습한 perceptron은 이론상 2개의 layer로 모든 함수를 표현할 수 있지만, 그것이 복잡하고 사람이 직접 가중치를 설정해야 한다는 문제가 있었다. 하지만 지금부터 다룰 신경망(Neural Network)은 가중치 매개변수의 값을 데이터로부터 적절하게 학습할 수 있다. 이번 장에서는 다음 것들에 대해 학습한다.
- 신경망의 개요
- 신경망의 입력 데이터 처리과정
매개변수를 학습하는 방법은 다음 장에서 다룬다.
4.1 Perceptron to NN(Neural Network)
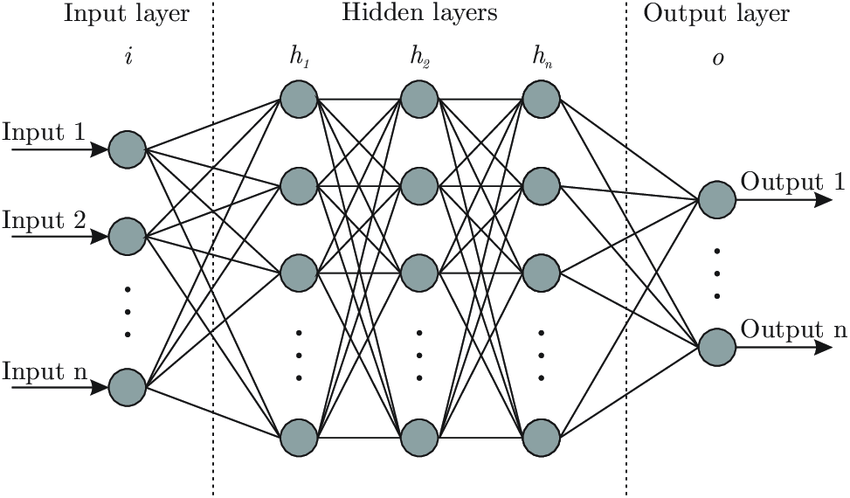
신경망은 perceptron과 닮은 점이 많다. 언뜻 밑의 <그림1>을 보면 그냥 multilayer percetron(MLP)이 NN이 아닐까 싶기도 하다. 실제로 NN을 MLP로 부르기도 하는데, perceptron과 닮은 점을 중심으로 NN의 구조를 알아보자.
NN을 MLP라고 부르는 것은 사실 잘못된 용어사용이다. 뒤에서 배우겠지만 NN은 logistic regression model(continuous nonlinearities)들의 집합이고 MLP는 perceptron(discontinuous nonlinearities)들의 집합이기 때문이다. [1]
4.1.1 Example of NN
일반적인 신경망을 그림으로 나타내면 다음 <그림1>과 같이 된다.
여기서
- 가장 왼쪽 줄을 입력층(input layer)
- 맨 오른쪽 줄을 출력층(output layer)
- 그 사이의 여러 층들을 은닉층(hidden layer)
이라 한다.
이 때 각 동그라미 유닛을 뉴런이라 부르고 input 신호는 입력에서 출력 방향으로 전달된다. 또한 perceptron과 마찬가지로 입력 신호는 n차원의 벡터일 수 있다. (output->input 방향으로 흐르는 신호도 존재)
이제, 신호 전달 측면에서 NN과 perceptron의 차이를 보기 위해 우선 퍼셉트론의 신호 전달 방법을 복습해보자.
4.1.2 Reminding perceptron
앞장에서 본 perceptron의 구조는 다음<그림2>와 같았으며,
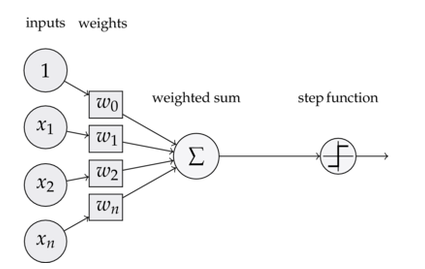
이 퍼셉트론의 출력을 threshold를 고려하여 써보면 다음과 같았다. b는 threshold를 이항한 -t를 새로 b로 정의한 것이다.
$$
y= 0 (\sum _{ i=1 }^{ n }{ w_ix_i }+b \le 0 ) , \quad1(\sum _{ i=1 }^{ n }{ w_ix_i }+b \ge 0)
$$
이 때 위의 y에 대한 식을 조금 더 다듬어 다음과 같이 함수화 할 수 있다.
$$
y=h(\sum _{ i=1 }^{ n }{ w_ix_i }+b)
$$
이 때 h(x)는 다음과 같이 정의되는 unit step function이다.
$$
h(x)=0(x\le0),\quad 1(x\ge0)
$$
(참고: unit step function에 대해서: https://hezma.tistory.com/83)
이 때 h(x)를 활성화 함수(activation function)라 하는데 perceptron은 h(x)로 step function을 이용한다고 볼 수 있다.
즉, input x에 대해 우선 weighted sum인
$$
s =\sum _{ i=1 }^{ n }{ w_ix_i }+b
$$
를 계산한 뒤
$$
y=h(s)
$$
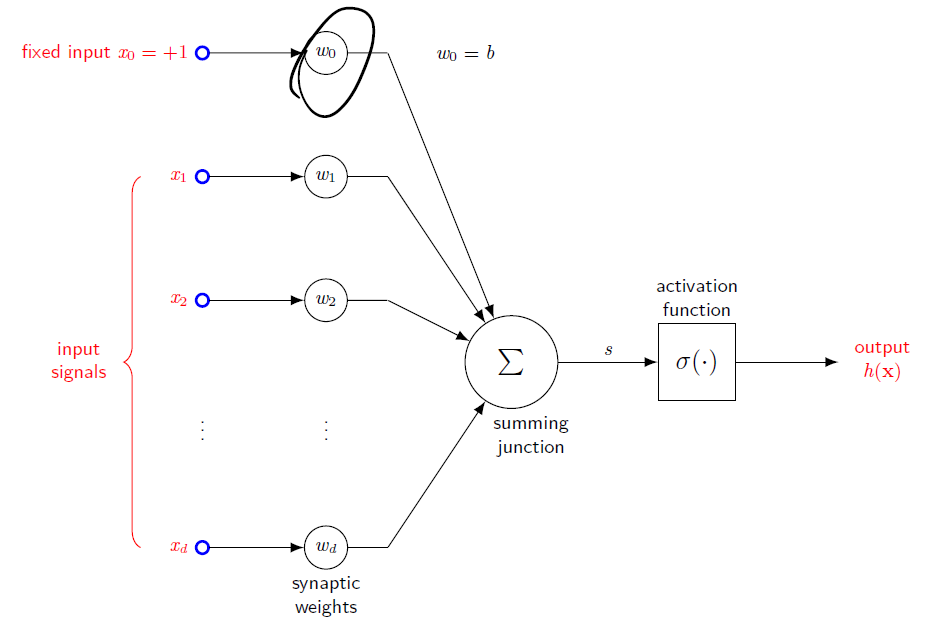
로 a가 activation function을 거쳐 결정된다고 볼 수 있다. 이 구조를 나타내보면 <그림3>과 같다.
4.2 Activation function(활성화 함수)
NN은 이런 활성화 함수를 가진 neuron을 여러개 쌓아 만든 구조다. 이 때 perceptron에서는 unit step function만이 activation function으로 쓰이지만 NN에서는 activation function으로 다른 다양한 함수들을 쓸 수 있다. 이 절에서는 다음의 활성화 함수들에 대해 알아보겠다.
- step function
- Relu
4.2.1 sigmoid function(시그모이드 함수)
sigmoid 함수는 다음과 같이 정의되는 함수다
$$
\sigma(s)=\frac{1}{1+exp(-s)}
$$
이를 다음 코드로 plot해보면 다음 <그림4>와 같이 나온다.
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1/(1+np.exp(-x))
x=np.arange(-5,5,0.1) # x input은 -5부터 5까지 0.1간격으로 찍기
y=sigmoid(x)
plt.plot(x,y)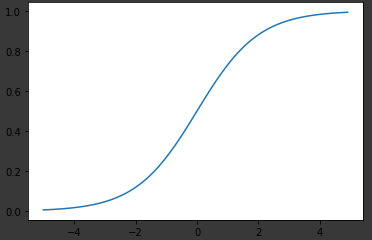
이런 함수를 왜 써야하는가에 대한 의문점이 많겠지만, 이후 gradient descent등 수학적 연산 방법에서 sigmoid의 여러 유용한 수학적 성질들이 식을 간단히 만드는데 도움이 된다.
-비선형 함수(nonlinearity function)
step function과 sigmoid function의 공통점은 둘 다 nonlinear function이라는데 있다. nonlinear function이란 y=ax처럼 linear한 함수가 아닌 함수를 뜻하는데, 신경망을 설계할 때 activation function으로는 nonlinearity function을 이용한다. 왜냐하면 선형함수는 층을 아무리 깊게 쌓아도 단층 네트워크로 똑같은 기능을 할 수 있기 때문. 간단한 예를 들어 y=ax라는 활성화 함수를 가진 NN을 생각해보자. 그럼 이걸 두층 쌓았을 때 y=a(a(x))=a2x 세층 쌓으면 3승, .... 로 되어서 앞의 상수만 결국 바뀔 뿐이다. 따라서 층을 쌓는 혜택을 얻을 수 없으므로 NN의 activation function으로는 nonlinear function만을 이용한다.
4.2.2 ReLU(Rectified Linear Unit) function
Relu는 다음과 같이 정의되는 함수로, 0보다 큰 x는 그대로, 아닌 x는 0을 반환하는 함수다.
$$
h(x)=x(x \ge 0),0(x\le0)
$$
이를 다음 코드로 plot 해보면 다음 <그림5>와 같다.
import numpy as np
import matplotlib.pylab as plt
def ReLU(x):
return np.maximum(x,0)
x=np.arange(-5,5,0.1)
y=ReLU(x)
plt.plot(x,y)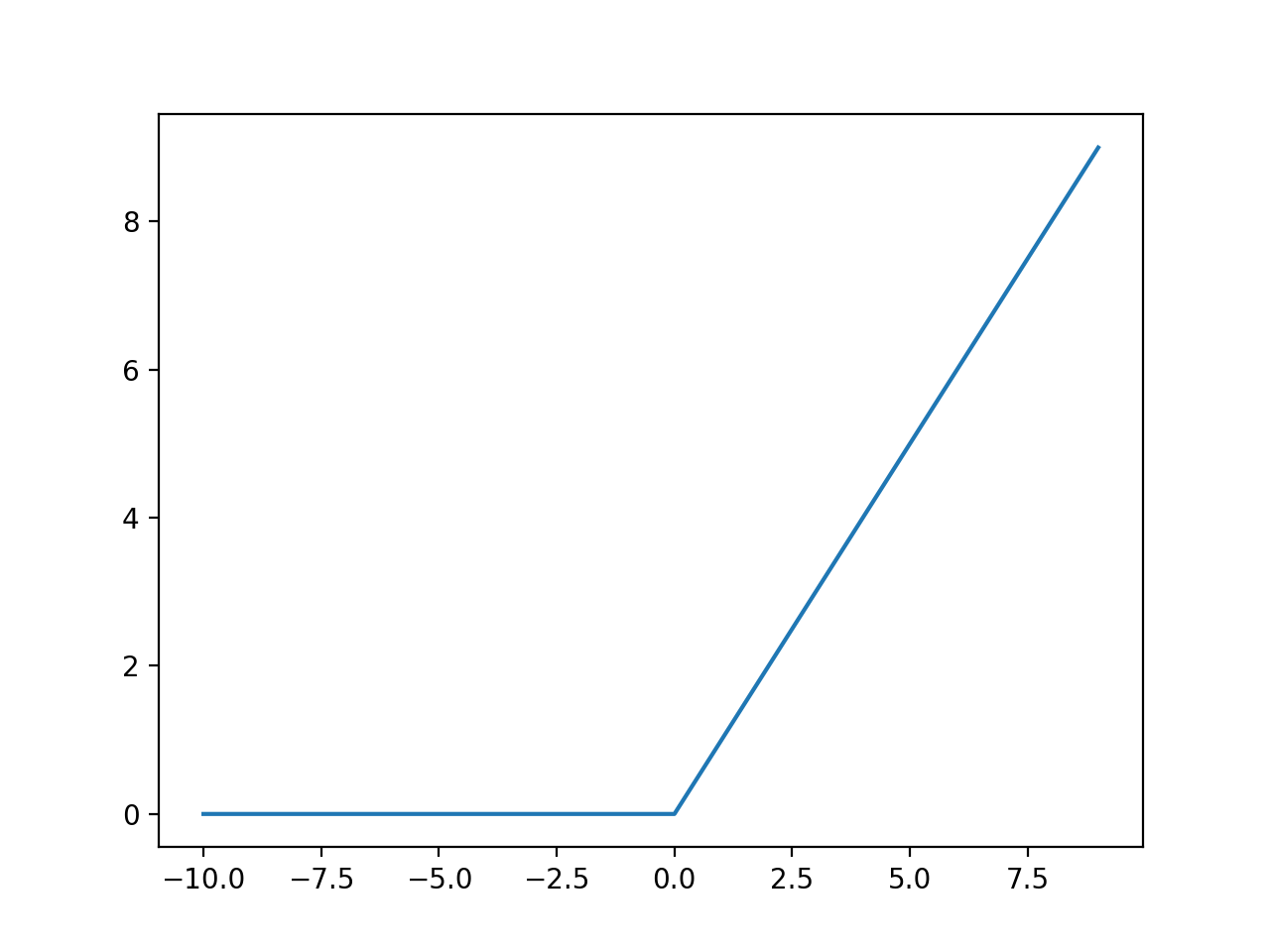
4.3 Architecture of Neural Network
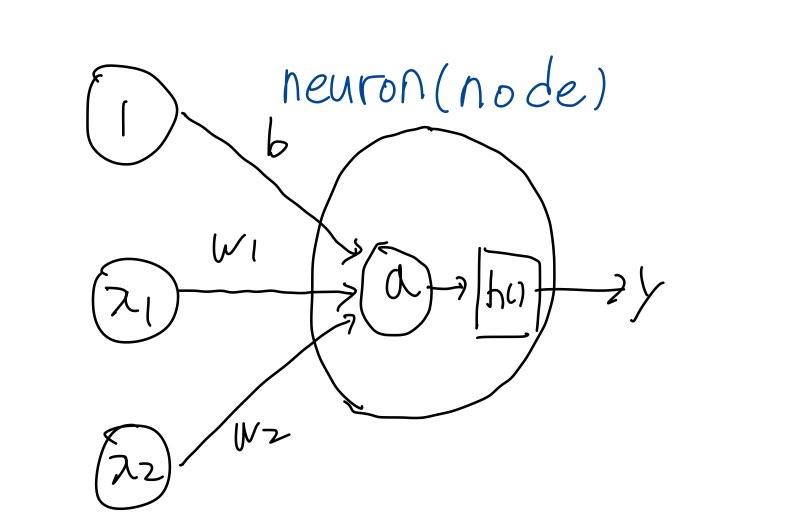
4.1에서 이야기한 뉴런의 정의를 다시 간략하게 정리해보면, 다음 <그림6>과 같았다.
이 때, NN은 다음<그림7>과 같이 뉴런이 여러개 모여 만들어진 Layer가 다시 층층이 쌓여 만들어진 구조였다.
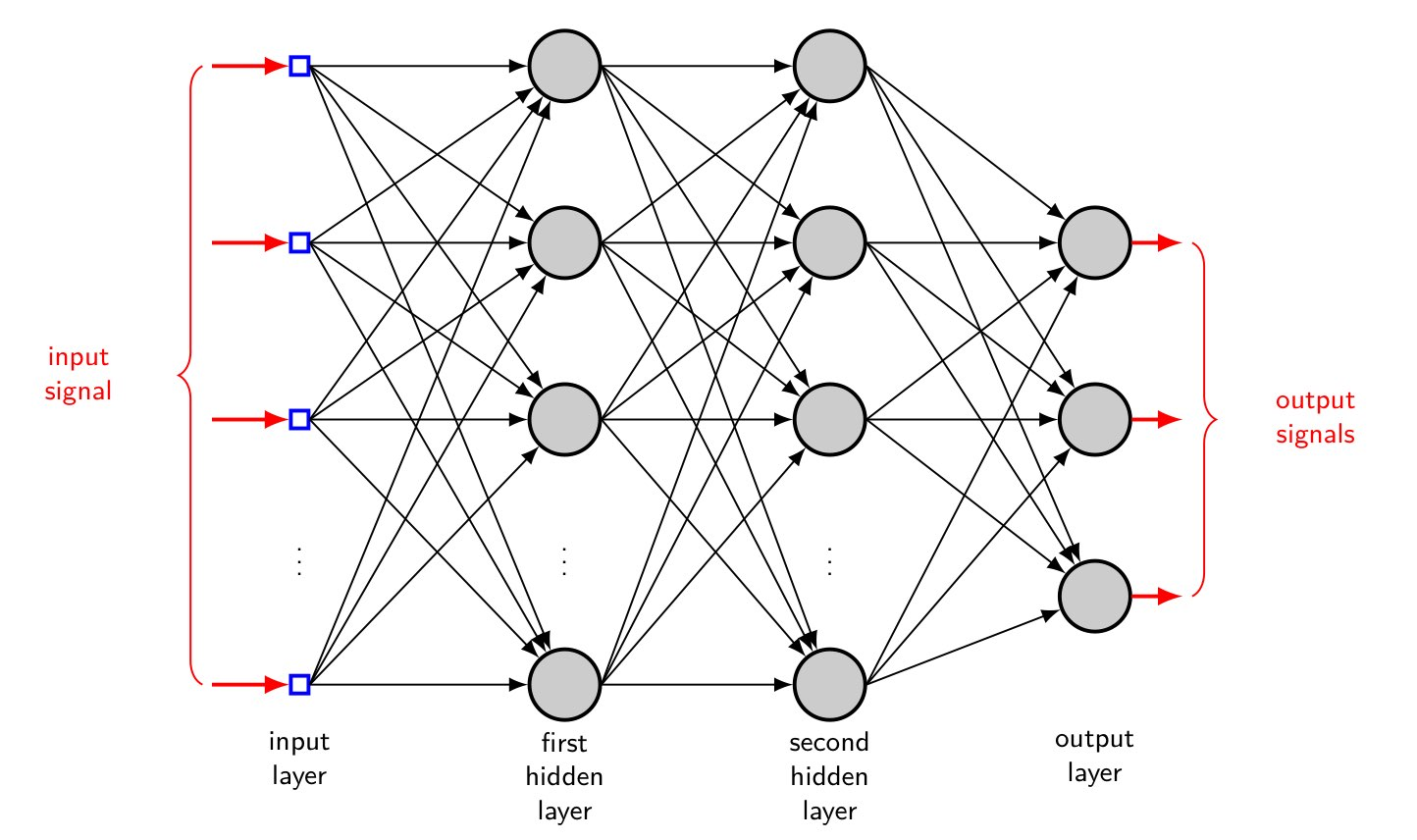
이 때 맨 왼쪽의 input signal을 바로 받아들이는 층을 input layer, 마지막 output signal을 출력하는 부분을 output layer라 하고, 그 사이에 있는 layer들을 hidden layer라 한다.
4.3.1 Types of Signals in NN
Neural Network에서는 두 가지 정보의 흐름이 존재한다. 다음 <그림8>은 그 정보의 흐름을 나타낸 것이다. 이 때 input->output 방향으로 흐르는 signal을 function signal, 반대를 error signal라 한다. 각 신호의 역할은 다음과 같다.
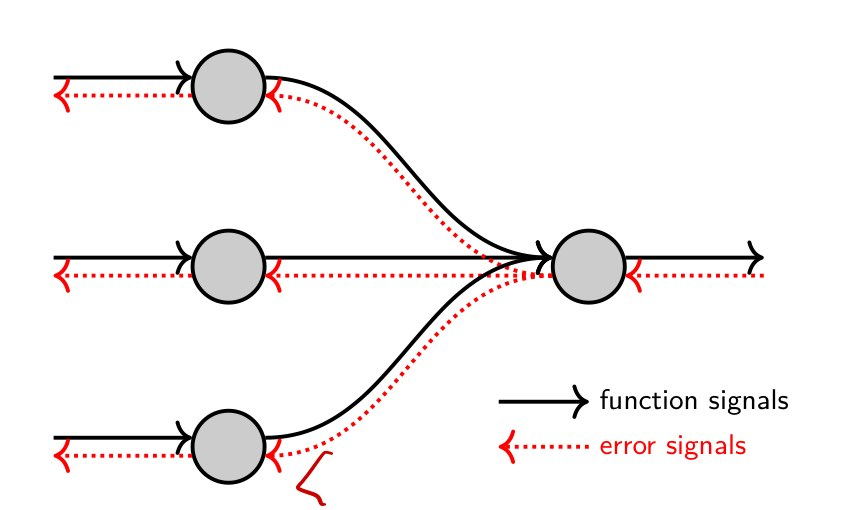
- function signal: 입력 data에서 출력 data를 계산하는 과정. forward propagation. predict에서 사용.
- error signal: 출력층에서 error를 feedback하여 각 뉴런의 weight를 조정하는 과정. backward propagation. training에서 사용.
4.3.2 Forward Propagation
위에서 두 가지 신호의 흐름에 대해 다루었다. 우선 input->output방향의 신호 전달 과정인 forward propagation을 다루고 backward propagation은 training을 소개하며 다루기로 한다. 다음 <그림9>와 같은 network를 보자. a1,a2,a3는 각 뉴런의 activation function을 거친 출력값이다.
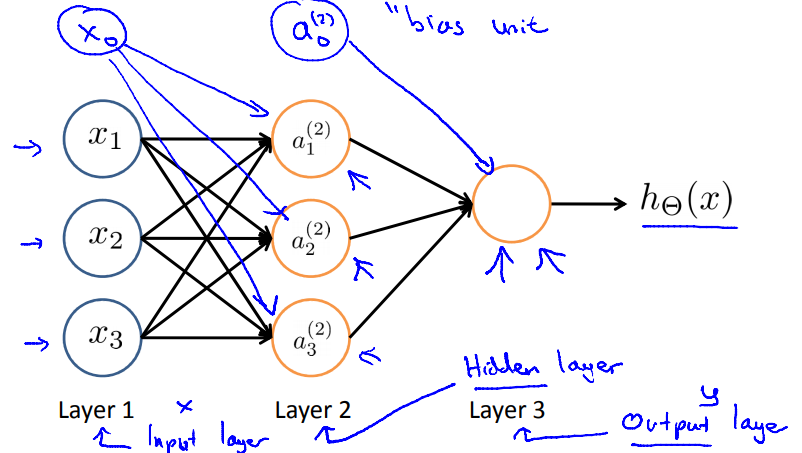
이 때 a1,a2,a3는 forward propagation에 의해 다음 <그림10>과 같이 계산된다. 다음 layer의 뉴런에 이전의 모든 neuron이 관여하는 것을 유의하여 보자. 이런 특성 때문에 일반적인 NN을 fully connected layer로 부르기도 한다. g()는 activation function이다.
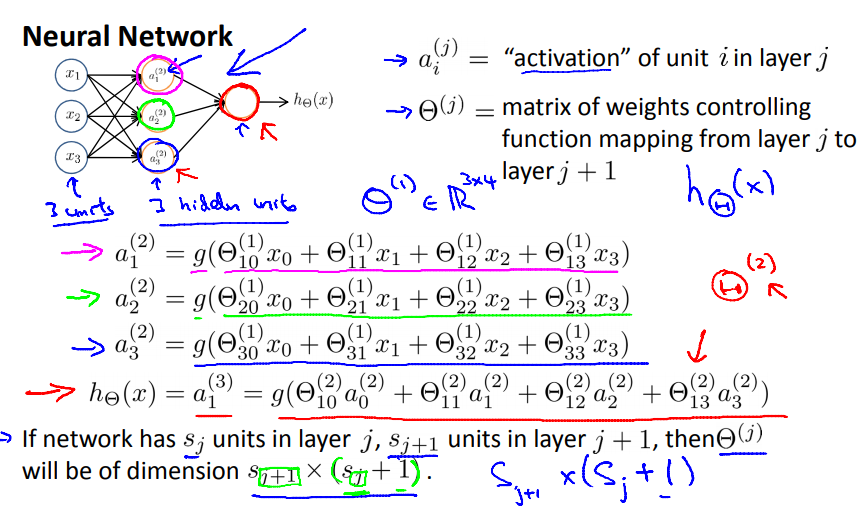
이 때 Θ 23 (1) 은 다음을 뜻한다. (그냥 표기법이므로 자신이 이해할 수 있는 규칙을 정해서 표기해도 된다.)
- 1번째 layer의 weighted sum을 구할 때
- 다음 layer의 2번째 뉴런에 들어가는 값 중
- 3번째 neuron의 출력 값에 곱해지는 weight.
이 때, vectorize implementation을 생각해보기 위해 다음과 같은 조건에서 이런 weight parameter들을 모아놓은 행렬을 생각해보자.
- k layer의 neuron수는 bias unit을 제외하여 생각했을 때 총 nk개
- k+1 layer의 neuron수는 bias unit을 제외하고 총nk+1개
이 때, k layer의 weighted sum을 계산하는 paramter들을 모아놓은 Θ (k) 는 nk+1 x (nk+1) 의 차원을 가져야 한다. (그림11을 보고 bias unit에 유의하여 생각해보자.)
이렇게 Θ (k)를 정의하면 다음 <그림11>과 같이 forward propagation과정을 vectorize할 수 있다.
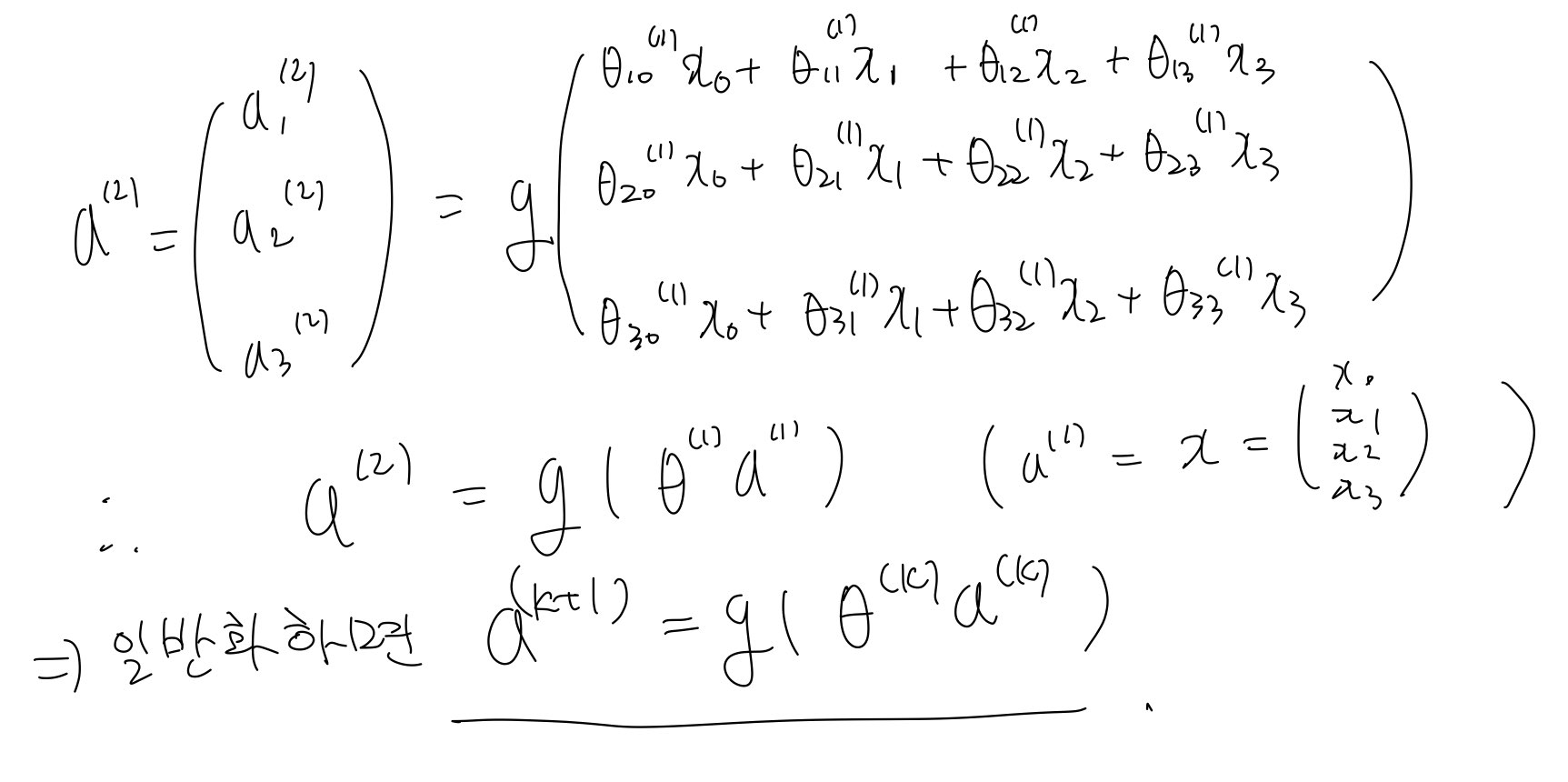
얘기가 길어졌지만, 결론은 다음의 계산을 기억하자는 것이다. (theta의 구성에 따라 theta를 transpose하여 곱해야 할 수도 있다.)
$$
{a }^{ (k+1) }=\theta^{(k)}a^{(k)}
$$
4.3.3 Designing Output Layer
신경망은 Classfication, Regression 문제에 모두 이용될 수 있지만, 어떤 문제냐에 따라 출력층에서 사용하는 activation function이 달라진다. 일반적으로
- Regression문제에는 Identity function(항등 함수)
- Classfication문제에는 SoftMax function
을 사용하게 된다.
** Classfication & Regression? **
Classfication(분류): 데이터를 특정 class로 분류하는 문제. ex) 사진 속 인물의 성별을 분류하는 문제
Regression(회귀): 데이터를 주었을 때 연속적인 output을 추출하는 문제 ex) 사진 속 인물의 키를 출력하는 문제-Identity & SoftMax function
(1) Identity function: 항등함수
항등함수는 입력을 그대로 출력하는 함수로 이러면 출력층에서 입력신호가 그냥 출력신호로 바로 보내진다.
(2) SoftMax function
SoftMax function은 출력층에 n개의 neuron이 있을 때 k번째 출력을 다음과 같이 정의되는 함수다.
$$
y_{k}=\frac{exp(a_k)}{\sum _{ i=1 }^{ n }{exp(a_i)}}
$$
이를 python으로 구현해보면 다음 코드와 같다. a와 y는 n차원 벡터다.
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return yexp에 의한 overflow문제를 방지하기 위해 지수법칙을 응용하여 분자와 분모를 벡터의 값 중 가장 큰 값으로 나눠주는 대책을 써서 다음과 같이 구현하기도 한다.
def softmax(a):
C=np.max(a)
exp_a = np.exp(a-C) # 수정된 부분
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y이 때 다음의 <그림12>와 같은 예를 보자.
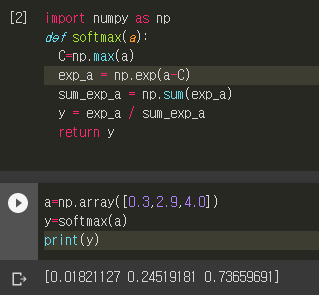
이 때 출력을 보면 몇가지 성질들을 알 수 있다.
- Softmax의 출력은 [0,1]의 실수
- 출력 vector의 원소 총합이 1
- 입력 원소의 대소 관계가 출력 원소에서도 유지.
이런 성질들은 Softmax의 출력 결과를 확률로 해석하는 것을 가능하게 한다.
-출력층의 뉴런 수 정하기
출력층의 뉴런 수는 문제에 맞게 정해야 한다. 예를 들어, 분류 문제에서는 주어진 Class의 개수만큼을 출력층의 수로 정하면 될 것이다.
4.4 Multiclass Classification
그럼 NN을 배웠으니, 미리 학습된 매개변수 값을 이용해 multiclass classfication을 진행해보자. 참고로 머신 러닝은 학습-추론 단계로 구성되는데, 학습은 training Data를 이용해 매개변수를 배우는 과정, 추론은 이미 학습된 매개변수를 이용해 새로 들어오는 Data들에 대한 출력을 계산하는 과정이다. 정리해보면 여기서는 추론 과정만 해본다.
4.4.1 Load MNIST Dataset(손글씨 숫자 인식)
다음 <그림14>에 있는 Data들을 실제 숫자로 분류해본다. 숫자는 0부터 9까지 있으므로 output layer의 뉴런 수를 10개로 정하면 될 것. 예제를 할 때 Data를 Load하거나 미리 학습된 매개변수를 이용하는 것은 다음 github를 참고했다.
Reference: https://github.com/WegraLee/deep-learning-from-scratch
이 링크에서 전체 코드를 받아 ch3 폴더 안에 코드를 작성하면 된다.
-1. Data Load & Import
# Main File of Mnist Classifcation
# 1. import
import sys,os
sys.path.append(os.pardir) # 상위 디렉토리 사용하게 하는 코드. 제공되는 load_mnist 함수를 사용하기 위함.
from dataset.mnist import load_mnist # MNIST DATA를 LOAD하는 함수.
from PIL import Image
import numpy as np
import pickle-2. Shape of Data
(x_train,t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False) # Data Load
print(x_test.shape) #(10000, 784)
print(t_test.shape) # (10000,1)이 예제에서는 test data만 볼 것이므로 train과 관련한 data는 제외하고 보자.
글자의 pixel은 28x28=784이므로 한 이미지의 크기는 784x1이 됨. 따라서 Data shape을 보면 test data는 총 10000개가 된다. t_test는 label로 정답을 뜻하는 것임. 해당 이미지에 적혀있는 숫자가 몇인지 알려준다.
-3. Arithmetic Functions
def softmax(a):
C=np.max(a)
exp_a = np.exp(a-C) # 수정된 부분
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
def sigmoid(x):
return 1/(1+np.exp(-x))계산시 써먹을 수학 함수들.
-4. Watch Image Data
def img_show(img):
pil_img= Image.fromarray(np.uint8(img)) # 1~255사이의 밝기 값이므로
pil_img.show()
img_number = 11 # 이걸 바꿔서 확인하면 됨.
img=x_train[img_number]
label=t_train[img_number]
print(label)
print(img.shape) # 784,1
img=img.reshape(28,28) # 원래 이미지 모양으로 변경
print(img.shape) # 28*28
img_show(img)
직접 image 데이터를 확인해보자. 위의 load_mnist함수는 28x28 데이터를 784*1 데이터로 변형하므로 우리도 PIL library 사용을 위해 Data를 다시 변경해주어야 한다.
-5. Function Related to Forward Propagation
def get_data(): # test data 가져오기
(x_train,t_train), (x_test, t_test) = load_mnist(flatten=True, normalize=False)
#(훈련 이미지, 훈련 레이블), (시험 이미지, 시험 레이블)
#이번 예제에서는 training이 필요 없으므로 test data만 갖고 옴.
return x_test, t_test
def init_network(): # sample weight를 network에 넣기.
with open("sample_weight.pkl",'rb') as f:
network= pickle.load(f)
return network
def predict(network, x): # forward propagation
## weight와 data를 이용한 계산으로 어떤 숫자일지 '예상'하는것
W1,W2,W3 = network['W1'], network['W2'], network['W3']
b1,b2,b3 = network['b1'], network['b2'], network['b3']
# network: dictionary 변수임.
#------FORWARD PROPAGATION----------#
z1 = np.dot(x,W1)+b1 # 첫 layer의 neuron값들 계산
a1 = sigmoid(z1) # activation function 거침.
z2 = np.dot(a1,W2)+b2
a2 = sigmoid(z2)
a3 = np.dot(a2,W3)+b3
y = softmax(a3)
#------------------------------------#
return y
-6. Calculate Accuracy
x, t = get_data()
network = init_network()
accuracy_cnt = 0
batch_size = 100
for i in range(0,len(x),batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network,x_batch)
p = np.argmax(y_batch,axis=1) # 0차원,1차원을 가진 y_batch에서 1번째 차원을 구성하는 각 원소들에서 최대를 반환하게 함.
#즉 p는 100*1배열이 됨.
accuracy_cnt += np.sum(p==t[i:i+batch_size]) # 배열 간 비교연산자 -> bool배열됨.
print("Accuracy:"+str(float(accuracy_cnt)/len(x)))
(batch로 처리. predict에 들어가는 data가 784xbatch_size가 됨.)
여기까지 NN의 구조와 사용되는 함수, forward propagation 과정에 대해 다루었고, training에 필요한 backward prop는 다음 챕터에서 다룬다.
Reference: [1] : NN-bishop by USTC(University of Tech and Science of China),
밑바닥부터 시작하는 딥러닝 by 사이토 고키, Machine Learning by Andrew Ng
'머신러닝' 카테고리의 다른 글
| [ML] 6. Back Propagation (2) | 2020.08.08 |
|---|---|
| [ML] 5. Training Neural Network (0) | 2020.08.06 |
| [ML] 3. Logistic Regression (0) | 2020.07.27 |
| [ML] 2. Binary Classification & Linear Regression (0) | 2020.07.23 |
| [ML] 1. Perceptron (0) | 2020.07.22 |
- Total
- Today
- Yesterday
- 머신 러닝
- NLP
- Andrew ng
- 사진구조
- 이산 신호
- 매트랩
- 신호 및 시스템
- 이미지처리
- gradient descent
- 딥러닝
- 머신러닝
- 신경망
- 영상처리
- CS
- 순환 신경망
- 영상구조
- rnn
- 이미지
- 매트랩 함수
- 인덱스 이미지
- 컴퓨터 과학
- ML
- 자연어 처리
- 밑바닥부터 시작하는 딥러닝
- 연속 신호
- Logistic Regression
- RGB이미지
- 컴퓨터과학
- Neural Network
- CNN
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |